23 相關性之考題
底下來看兩道學測數學科裡涉及“相關性”之試題。第一道是104學年的多選題:
小明參加某次路跑10公里組的比賽,下表為小明手錶所記錄之各公里的完成時間、平均心率及步數:
|
完成時間 |
平均心率 |
步數 |
|
第一公里 |
5:00 |
161 |
990 |
|
第二公里 |
4:50 |
162 |
1000 |
|
第三公里 |
4:50 |
165 |
1005 |
|
第四公里 |
4:55 |
162 |
995 |
|
第五公里 |
4:40 |
171 |
1015 |
|
第六公里 |
4:41 |
170 |
1005 |
|
第七公里 |
4:35 |
173 |
1050 |
|
第八公里 |
4:35 |
181 |
1050 |
|
第九公里 |
4:40 |
171 |
1050 |
|
第十公里 |
4:34 |
188 |
1100 |
在這10公里的比賽過程,請依上述數據,選出正確選項。
(1)由每公里的平均心率得知小明最高心率為188。
(2)小明此次路跑,每步距離的平均小於1公尺。
(3)每公里完成時間和每公里平均心率的相關係數為正相關。
(4)每公里步數和每公里平均心率的相關係數為正相關。
(5)每公里完成時間和每公里步數的相關係數為負相關。
“大考中心”提供的答案是(2)、(4)、(5)。
先檢視5個選項的敘述。由於題目中的數據,都是關於小明在“某次”路跑賽裡的資料,所以也只能得到有關小明在該次路跑的推論。但選項(1)及(2),是問小明如何,選項(3)、(4)及(5),卻皆未提到“小明”,兩相對照,會讓人以為(3)、(4)及(5),是針對一般人的體能提問,這是命題者之疏失。另外,在選項(2)裡,於“小明”之後,有“此次路跑”4字,選項(1)、(3)、(4)及(5)裡則沒有,再度,會讓人以為選項(1)、(3)、(4)及(5),是針對一般情況之提問,而不僅是有關小明此次路跑的這組樣本。所以,若依現有題目之敘述,有學生遵循邏輯,未選(1)、(3)、(4)及(5),應該算是對的。所以5個選項裡,都該有“小明此次路跑”幾字才完整。雖是屬於注重邏輯的數學科,但命題者對題目之敘述,顯然相當不謹慎。
要知這只是一次路跑的數據,若小明再跑一次,或繼續跑10公里,將可能得到完全迥異的數據。因而所得之樣本相關係數,連正負號說不定都會反過來。這有如假設題目裡說“投擲一銅板10次,得到5個正面”,則若問“銅板出現正面的機率為0.5?”,便不該選,要選也是還諸如提問“可以0.5做為銅板出現正面機率之估計值嗎?”。也就是不論投擲多少次,得到的都只是銅板出現正面機率之估計值。那能辯解機率有不同的意義,這裡乃指主觀的解釋嗎?若是這樣,則有沒有選此選項,便都該給分了。事實上,依據此次實驗所計算出來的只是樣本之相關係數,可做為母體相關係數之估計值。至於母體之“每公里完成時間和每公里平均心率”,及“每公里步數”和“每公里平均心率”,是否為正相關或負相關,並無法由題目所給之小明跑10公里後的數據得知。
再給一文字方面的問題。兩個變數間,才有所謂正相關、負相關,或無相關可言。至於相關係數,不過是一個數字,可能為正、負或0。因此在選項(3)、(4)及(5)裡,問“相關係數是否為正相關(或負相關)”並不恰當,宜問相關係數是否為正(或負);或者 “的相關係數”5字全刪除。猜想命題者並不熟悉“相關係數”此一題材。
在學測如此大型的考試,命題者對文字的陳述顯得過於隨意,尚非本題最關鍵的缺失。要知就算題目寫得不清不楚,早已身經百戰的台灣中學生,大致能猜出命題者的意思。假設某人想觀察自己體重的變化,遂每天量測並記錄。能否想到該注意些什麼?有的!須儘量在相同的情況下量測。例如,每天皆在剛起床時量測,這樣才較能相比。即使如此,每天起床時間可能有差異,或有些日子前一晚因應酬吃喝較多,因而就算採取固定時間量測,恐怕也不敢宣稱,確實做到每天在相同的情況下記錄,但至少已儘量了。如今題目一開始便敘明,小明是參加比賽。而眾所皆知,比賽有競爭,跑者大抵會依自己體能去配速。甚至,人非汽車也非機器,連續跑10公里,豈能維持每1公里的狀況都相同?因此,少有以如題所述的方式,收集個人數據並做分析。若每天在差不多同一時間跑1公里,量測3項數據,連跑10天,再分析所得的數據,還較合理些。出這種考題,可說易教壞學生的統計概念。話說回來,僅以少少的10筆數據,便大做分析,也未免不像個統計分析。
資料收集為統計分析裡,一重要的步驟。惟有秉持很嚴謹的態度,如此取得的數據,方能準確客觀,而得到的推論,也才較具參考價值。就如醫學上,一種新藥或新技術,想知其效果如何,便需找人做實驗。但並非徵求自願,來者不拒。實務上,不僅須謹慎挑選受測樣本,且實驗過程須有一定規範。而對某議題進行一項民調,也並非就站在商區街頭,任意找願意受訪者填寫問卷,或拿起電話便撥,誰接便問誰,若沒人接就再打下一通。取樣須很嚴謹,才能得到有意義的結果。
最後,對於上述考題,可否“假設”小明每一公里,都維持相同的狀態?亦即假設10筆數據(指完成時間、平均心率及步數)間為相互獨立。前面已說了,若加上這樣的假設,則便是數學而非統計題目了。總之,考試畢竟引導學習,高中生若常接觸這類題目,將難具備統計素養。
再看一道是106學年學測的單選題:
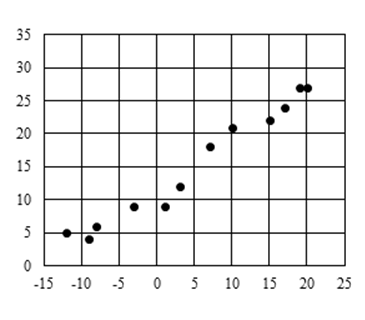
下圖是某城市在2016年的各月最低溫(橫軸)與最高溫(縱軸)的散佈圖。
https://upload.cc/i1/2021/11/14/5HUnrC.png
今以溫差(最高溫減最低溫)為橫軸且最高溫為縱軸重新繪製一散佈圖。試依此選出正確的選項。
(1)最高溫與溫差為正相關,且它們的相關性比最高溫與最低溫的相關性強。
(2)最高溫與溫差為正相關,且它們的相關性比最高溫與最低溫的相關性弱。
(3)最高溫與溫差為負相關,且它們的相關性比最高溫與最低溫的相關性強。
(4)最高溫與溫差為負相關,且它們的相關性比最高溫與最低溫的相關性弱。
(5)最高溫與溫差為零相關。
“大考中心”提供的答案是(4)。
由所給最低溫x與最高溫y之散佈圖,不難看出(採目測近似值)最高溫y愈小時,溫差y-x愈大。如y=5時,x為-12, 因而y-x= -17;y=27時,x=19,20,y-x=8,7。由於是單選題,故知答案必為(3)或(4)之一,因最高溫與溫差只能為負相關。至於相關性強弱之比較,就不易以如此簡單的方式看出。新的圖就不給了,不過若繪出最高溫與溫差之散佈圖,將發現此新圖,12個點大致由左上往右下散佈,即最高溫與溫差兩變數的確為負相關。另外,沿一直線散佈的情況,“感覺上”沒有原圖那麼明顯,因而判斷出最高溫與溫差的相關性,比最高溫與最低溫的相關性弱。
必須一提的是,題目所給散佈圖上的點畫得太大,在繪最高溫與溫差之散佈圖時,對緊張的考生不利就不說了。但此題之缺失並不在此,而是沒什麼統計的味道。人們對父親身高與兒子身高、入學成績與大一成績、每日最高溫與翌日清晨最低能見度、每日心血管死亡人數與當日溫差等,會想了解其相關性。另外,求一天之最高溫與最低溫的相關性,也尚可想出理由。日溫差令人感興趣,月溫差可能就較無感了。至於為什麼會去求各月份最高溫與最低溫,此二極端值之相關性,本就已不清楚了,由此進而去求各月份最高溫與溫差之相關性,便更是目的不明了。顯然只是因有了X與Y之相關性,便去求Y-X與Y之相關性。再度,這是數學思維,而非統計思維。
近年統計被大量引進高中數學課程後,應是覺得高中學生該多懂些統計。只是由上述兩道學測題目,顯示在中學數學裡,統計不過被視為一類計算簡單的數學看待,如此是無法讓學生學到正確統計概念的。與其這樣,還不如將統計移出中學數學,免得讓學生學壞了。
附錄。
統計裡引進相關係數,主要是量測兩變數間之線性相關性(linear correlation),包含強度及方向。相關係數取值介於-1至1間。若取正值,兩變數便稱正相關;若取負值,兩變數便稱負相關;而當相關係數為0,則稱兩變數無相關。線性關係是一很簡單的關係,加上前述符合度量需求的性質,因此不只在統計裡,在很多科學的領域,都廣被採用來量測兩變數的線性相依程度。由於是為英國統計學家皮爾生(Karl pearson,1857-1936)首創,且為有別於統計裡其他不同定義的相關係數,有時稱為“皮爾生相關係數”(Pearson’s correlation coefficient,又稱Pearson’s r)。
假設有兩個隨機變數X,Y,其共變異數(covariance) Cov(X,Y),與兩變數的標準差σX,σY之商,便是相關係數。在此
Cov(X,Y)=E[(X-μX)(Y-μY)]=E(XY)- μXμY,
其中μX及μY,分別為X,Y之期望值。若以ρ表X與Y之相關係數,則
ρ=Cov(X,Y)/(σXσY)= E[(X-μX)(Y-μY)/(σXσY)=E[((X-μX)/σX).((Y-μY)/σY)]。
由上式知,相關係數即兩隨機變數經“標準化”(減去期希望值,再除以標準差)後,乘積之期望值。由於標準化後之隨機變數,期望值為0,標準差為1,所以相關係數,可視為兩隨機變數標準化後之共變異數。兩非退化隨機變數X與Y,相關係數要存在,先決條件是,X與Y之期望值及變異數都存在。
可看出Cov(X,X)=Var(X)。即自己跟自己的共變異數,就是變異數。因此共變異數的概念,乃變異數之推廣。如果變異數,是用來度量一隨機變數偏離期望值的程度,則共變異數,便能度量二隨機變數同時偏離各自期望值的程度。若X > μX時,較可能使Y > μY,且若X < μX時,較可能使Y < μY,也就是說X與Y,有同時增大或同時減小之傾向,則(X-μX)(Y-μY)便較可能是正的,因而它的期望值Cov(X,Y)也就較可能為正。反之,若較大的X,有伴隨較小的Y之傾向,且較小的X,有伴隨較大的Y之傾向,則(X-μX)(Y-μY)便較可能是負的,因而它的期望值Cov(X,Y),將較可能為負。也就是Cov(X,Y)之正負,能反映X與Y之增長方向,究竟傾向相同或相反。由於標準差為正值,所以相關係數與共變異數符號相同,且二者同時為0,或同時不為0。因此相關係數為正或為負,分別顯示X與Y之增大與減小的傾向,相同或相反。
我們說過,對二隨機變數X與Y,共變異數是用來度量它們同時偏離各自期望值的程度。但與變異數類似,其值與所採用的尺度有關。例如,對於父與子身高的共變異數,身高單位採用公分,與採用公尺,前者之共變異數為後者之1萬(=1002)倍。不過一旦除以兩標準差後,得到的相關係數,便無此困擾了。相關係數ρ,永遠取值在區間[-1,1]。當ρ很接近0,表X與Y的線性關係較弱;而當ρ很接近1,或很接近-1,表X與Y有較強的線性關係,或者說相關性較強;ρ較接近0時,便表X與Y有較弱的線性關係,或者說相關性較弱。事實上,當ρ=1,或-1,X與Y便有完美的線性關係,或者說X與Y為完全相關(completely correlated)。即對二隨機變數X與Y,若ρ=1,則存在常數a,b,其中a>0,使得Y=aX+b;若ρ=-1,則存在常數a,b,其中a<0,使得Y=aX+b。曾有報導,同卵雙胞胎,若性別相同,則身高的相關係數很高,達到0.95,這乃可以預期。至於大學成績與將來收入多寡的相關係數,就不見得太高了,且說不定是負的。
另外,當X與Y獨立時,Cov(X,Y)=0,因而ρ(X,Y)=0。但其逆不真。也就是說,共變異數(或相關係數)為0,此時兩隨機變數為無相關,但不必然獨立。甚至,二隨機變數即使無相關,也不表二者沒有關係。例如,自區間[-1,1]隨機地取一個點,以X表之,再令Y=X2。Y是X的平方,二者顯然關係無比密切,一旦知道X,Y便完全決定了。但底下來看X與Y卻為無相關。因X為一對稱的隨機變數,故E(X)=0,且E(XY)=E(X3)=0,因而Cov(X,Y)=0,即得X與Y為無相關。這種例子很多,可參考一般機率論的書。仍要強調,相關係數雖說是量測二隨機變數之關連程度(degree of association),但主要是反映二隨機變數間,線性關係之強度及正負,而非反映任何其他關係。
對於數據,亦可定義其相關係數。設有(x1,y1),(x2,y2),…,(xn,yn),且分別以̄x,̄y表其平均值,則數據x’s,與y’s之相關係數,一般表示成r,定義為
r = Σni=1(xi -̄x)(yi-̄y)/[(Σni=1(xi -̄x)2)1/2(Σni=1(yi -̄y)2)1/2]。
例如,設有數據(1,5),(3,9),(4,7),(5,1),(7,13),則
̄x=4,̄y=7,且
(1-4)2+(3-4)2+(4-4)2+(5-4)2+(7-4)2=20,
(5-7)2+(9-7)2+(7-7)2+(1-7)2+(13-7)2=80,
(1-4)(5-7)+(3-4)(9-7)+(4-4)(7-9)+(5-4)(1-7)+(7-4)(13-7)=16。
故得
r = 16/(20.80)1/2=0.4。

{kind=link}